🧠 LeWorldModel (LeWM): Stable End-to-End JEPA from Pixels
Paper: arXiv:2603.19312 | Authors: Maes, Le Lidec, Scieur, LeCun, Balestriero
This interactive Space explains LeWorldModel — a Joint-Embedding Predictive Architecture (JEPA) world model that learns directly from raw pixels using only 2 loss terms and 1 hyperparameter.
How LeWorldModel Works
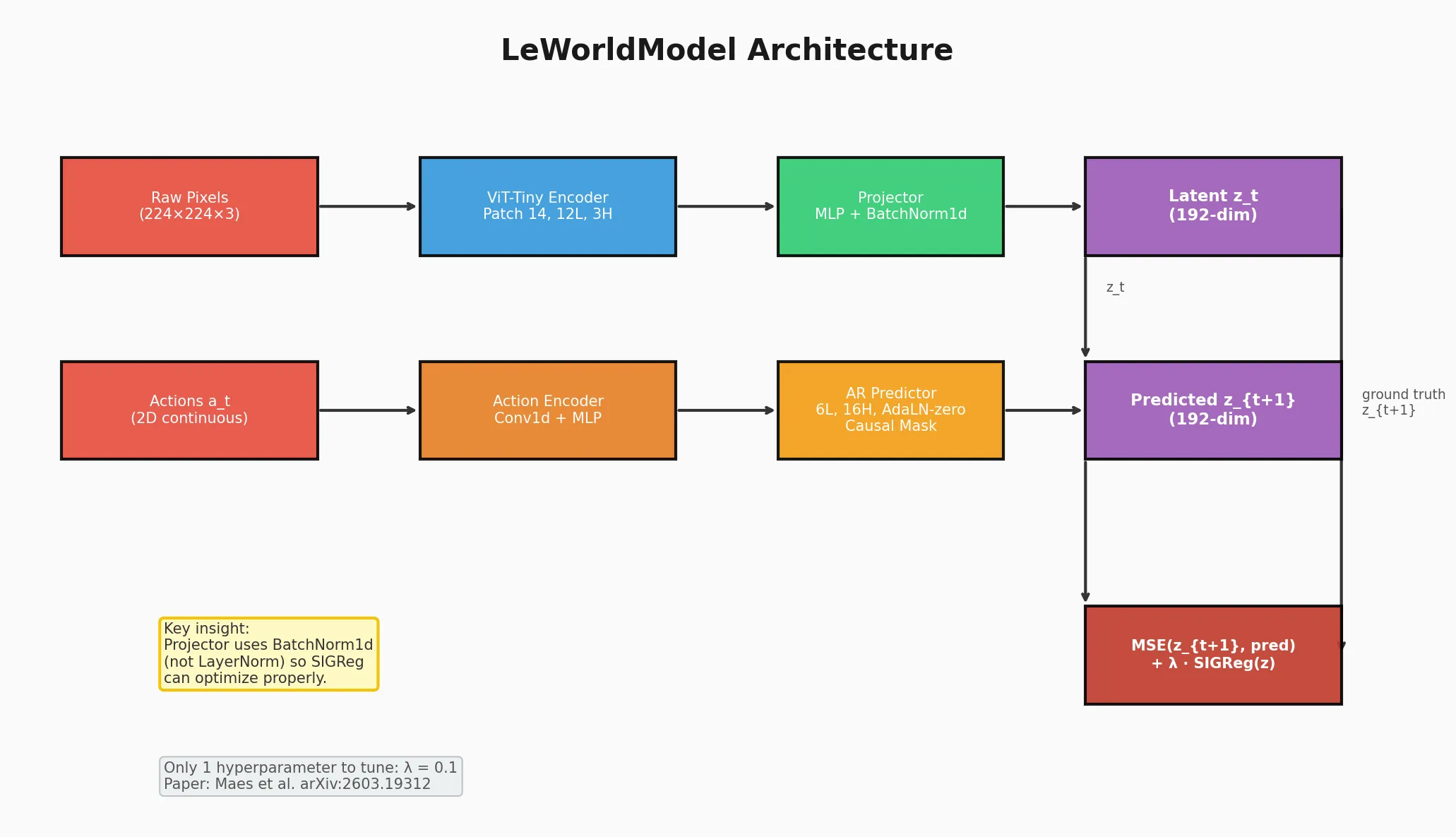
LeWM is composed of three main parts:
- Encoder (ViT-Tiny): Compresses 224×224 RGB frames into 192-dim latent vectors via [CLS] token + projector
- Predictor (6-layer Transformer): Predicts next latent state conditioned on actions via AdaLN-zero
- SIGReg: Anti-collapse regularizer that forces latents toward N(0, I) via the Epps-Pulley test
The key insight is the BatchNorm1d projector — because the ViT already ends with LayerNorm, using another LayerNorm would block SIGReg from optimizing. BatchNorm1d allows gradient flow.
{kind=link}
Training objective:
L = MSE(z_{t+1}, pred) + λ · SIGReg(z)
λ = 0.1is the only tunable hyperparameter- No stop-gradient, no EMA, no pre-trained encoders needed
- 48× faster planning than DINO-WM in latent space
Reference: Maes et al., "LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels", arXiv:2603.19312
Implementation: https://huggingface.co/ar27111994/lewm-implementation